



Auto-scaling is a technique that automatically adds or removes computing resources to maintain steady performance while controlling costs.
What is auto scaling used for?
Auto-scaling helps organizations achieve several key benefits:
- Sustain traffic spikes: Automatically adjusts computing resources (such as servers or containers) to match real-time demand.
- Improve reliability: Replaces failing instances/pods and distributes load to reduce single points of failure.
- Maintain performance stability: Keeps latency, queue time, and CPU utilization close to the target level.
- Simplify operations: Reduces manual capacity changes, enables safer rollouts, and makes experimentation easier.
How does auto-scaling work?
A control plane (such as a cloud service or orchestrator) monitors metrics (e.g., CPU usage, memory, requests per second, queue length, or custom business KPIs). When predefined rules are met, it scales out (adds instances/pods) or scales in (removes them).
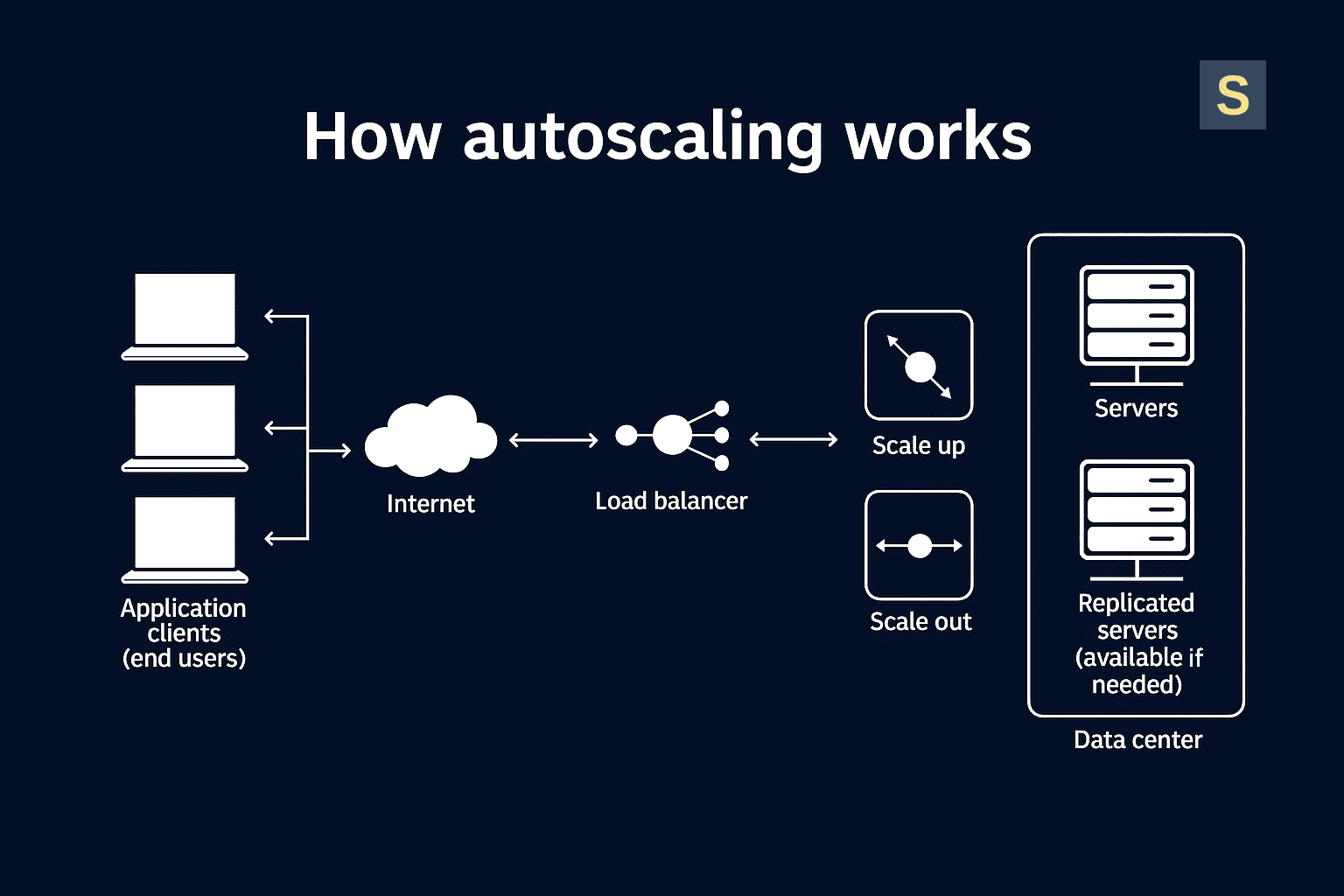
Key mechanics:
- Policies: Threshold-based rules, target tracking (e.g., keep CPU ~60%), scheduled scaling, or predictive models.
- Bounds: Minimum, desired, and maximum capacity limits prevent runaway scaling.
- Health & readiness: You can route traffic only to healthy and ready units; failing ones are replaced automatically.
- Cooldown and stabilization windows: Prevent rapid oscillation (“flapping”) by enforcing delays between scaling actions.
It is important to separate stateless tiers (easy to scale) from stateful tiers (may need vertical or sharding).
Types of auto-scaling
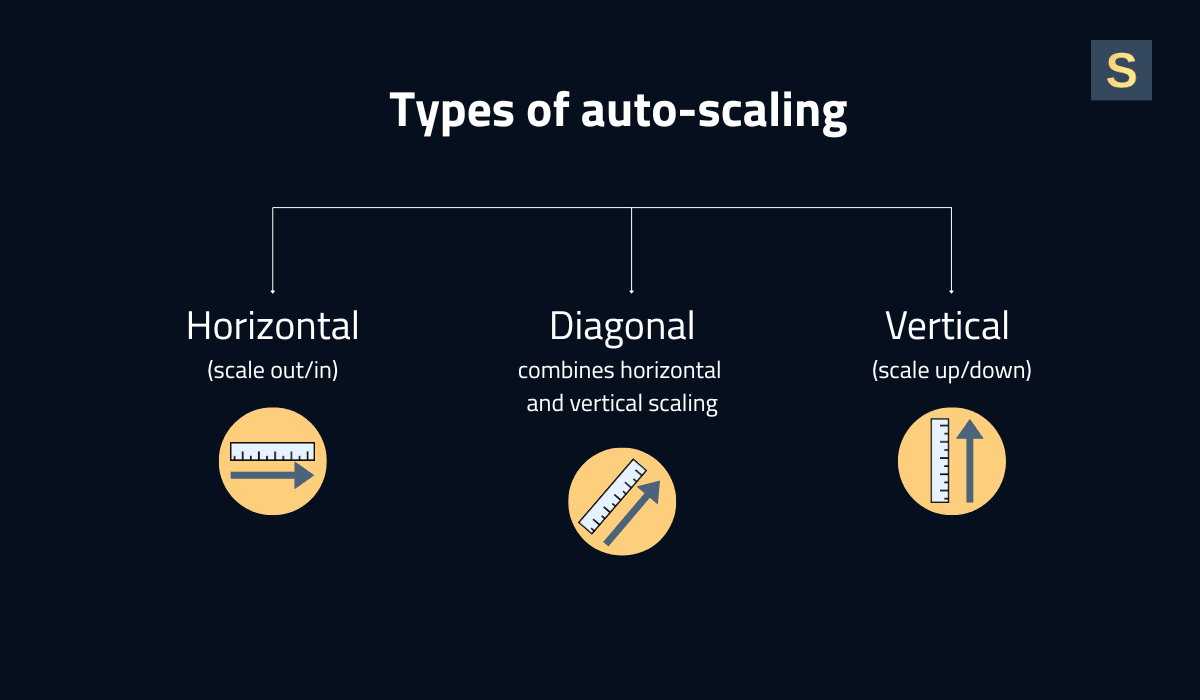
By scaling direction, auto-scaling can be divided into the following types:
- Horizontal (scale out/in): Increases or decreases the number of instances/pods. This is the most common and usually the most downtime-friendly option.
- Vertical (scale up/down): Changes the size (CPU/RAM) of a unit. Useful for stateful or single-threaded workloads.
- Diagonal: Combines horizontal and vertical scaling to balance cost and flexibility.
Depending on the trigger, you can use the following types of auto-scaling:
- Reactive. Auto-scaling reacts to metric thresholds (simple and dependable).
- Target tracking. Auto-scaling maintains a metric at a set point (e.g., 70% CPU).
- Scheduled. Auto-scaling introduces scheduled changes for known peaks (e.g., business hours).
- Predictive. Auto-scaling predicts demand and scales in advance.
- Queue-based. Auto-scaling scales on backlog/lag (typical for workers/ETL).
Auto-scaling vs load balancing: what's the difference?
A load balancer sits in front of your resource pool and distributes incoming traffic across available targets to balance usage, mask failures, and reduce latency. This way, you ensure requests are routed to healthy targets.
Auto-scaling adjusts the number or size of those targets. It can add or remove instances/pods (horizontal scaling) or resize them (vertical scaling) based on policies tied to metrics such as CPU, requests per second (RPS), or queue depth. Capacity limits (min/desired/max) and cooldowns prevent excessive scaling.
A load balancer can't create capacity. If all backends are loaded, it just redistributes pain. At the same time, auto-scaling without a balancer risks hotspots and slow, unbalanced warm-ups.
In practice, you route traffic through a load balancer for fault tolerance and even load distribution. You pair it with auto-scaling so the capacity matches demand.
How to configure auto scaling step-by-step?
We divided this process into 9 steps:
- Choose your platform.
- Define SLOs and metrics. Specify what “good” performance looks like (e.g., p95 latency < 300 ms, CPU 60–70%, queue length < 100).
- Set up observability and alerts. Monitor utilization, saturation, and error rates with dashboards, and configure alerts for throttling, OOM kills, or flapping.
- Select policies. This includes thresholds (e.g., scale out if CPU > 70% for 2–3 minutes), target tracking (keep metric at X), and schedules for known spikes (predictive if possible).
- Create templates. Launch template/instance image or Deployment/Requests/Limits.
- Configure health checks. Also, consider Kubernetes readiness/liveness probes.
- Cooldown/stabilization. Add scale-in/out delays (e.g., 300–600 s) to avoid oscillation.
- Integrate load balancing. Bind to ALB/NLB/Ingress so new capacity receives traffic only when available.
- Test & tune. Perform a synthetic load. Then, inspect step sizes, warm-up period, and cost effects. Repeat the process to get the best result.
You must regularly review limits and schedules since traffic patterns may shift.
Check out more SaaS terms in our SaaS glossary for business leaders.
Build and scale your software products with Seedium
Seedium is a trusted web & mobile development company that helps businesses build and scale their software solutions. Since 2017, we have successfully launched over 200 products in more than 15 industries, including SaaS, HRTech, and HealthTech.
Seedium offers a wide range of design & development services to help you achieve your business goals efficiently:
- Web & mobile application development;
- UX/UI & product design;
- Custom software development & integrations;
- AI development;
- Scaling product architecture;
- Providing dedicated development teams.
Feel free to contact us to start a conversation about your project. Let’s build something great together!



